1.数据库自增ID的弊端
- 暴露业务数据,比如用户表采用自增ID,别人可以根据ID知道系统有多少用户
- 分库分表时无法保证ID唯一性
2.需要什么样的ID生成策略
- 全局唯一
- 有序性
- 高性能,生成ID时延低
- 可扩展,支持数据库水平扩展
- 安全性,不能暴露业务数据
3.几种ID生成方案
3.1.UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,
优点:
- 性能非常高,本地生成,没有网络消耗。
缺点:
- UUID无法保证趋势递增;
- 信息不安全,基于MAC地址生成UUID的算法可能会造成MAC地址泄露
- UUID过长,往往用32位字符串表示,占用数据库空间较大,做主键的时候索引中主键ID占据的空间较大;
- UUID作为主键建立索引查询效率低,常见优化方案为转化为两个uint64整数存储或者“折半存储”(折半后不能保证唯一性);
- 由于使用实现版本的不一样,在高并发情况下可能会出现UUID重复的情况;
3.2SnowFlake算法
3.2.1.概念
twitter的SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图: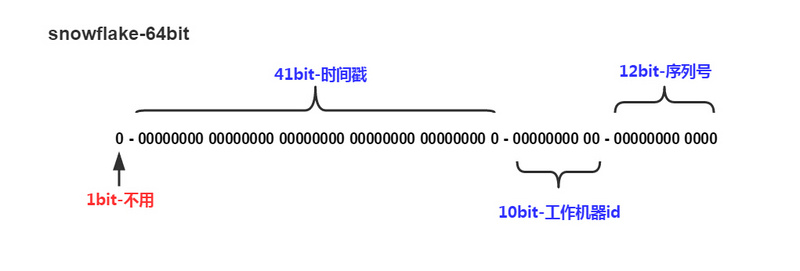
- 1位,不用。二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0
41位,用来记录时间戳(毫秒)。
- 41位可以表示2^41个数字,数值范围:0 至 2^41−1。
- 也就是说41位可以表示2^41 个毫秒的值,转化成单位年则是(2^41)/(1000∗60∗60∗24∗365)=69年
- 41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的
10位,用来记录工作机器id。
- 可以表示2^10=1024台机器
- 机器id可以是进程级别的,
- 机器级别的话,可以使用机器的mac地址或ip地址经过算法;如果是进程级别的话,可以使用path+进程标识;也可以混编,列如前5位datacenterId标识机器,后5位workerId标识进程
12位,序列号,用来记录同毫秒内产生的不同id。
- 12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生2^12=4096个ID序号
- 如果一个毫秒内,序列号已经达到上限,就等到下一毫秒,同时序列号置零开始
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高
3.2.2.JAVA实现
|
|
3.2.3.优缺点
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
3.3.数据库生成
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,先创建单独的数据库(eg:ticket),然后创建一个表:
|
|
获取ID:
|
|
为了避免单点,可以启用多台数据库服务器来生成ID,比如两台,设置步长step为2:
|
|
这种方案优缺点:
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- 水平扩展困难,定义好步长后如果想增加机器就非常麻烦
- 数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能
- ID没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍。
3.4.Mongdb ObjectId
和SnowFlake类似方法,Mongdb ObjectId 是一个12字节 BSON类型数据,有以下格式:
- 前4个字节表示Unix时间戳
- 接下来的3个字节是机器标识码
- 紧接的两个字节由进程id组成(PID)
- 最后三个字节是随机数。
示例:4e7020cb7cac81af7136236b,这个24位的字符串,虽然看起来很长,也很难理解,但实际上它是由一组十六进制的字符构成,每个字节两位的十六进制数字,总共用了12字节的存储空间。
这种方案优缺点如下:
优点:
- 保证ID唯一递增,信息安全也有保障
缺点:
- 依赖Mongdb,实现相对繁琐
- 存在网络消耗,性能不高
- 存储空间相对较大
- 作为中心化分配全局ID,必须由机器保障其功能可靠性,需要考虑水平扩展
3.5.基于redis的分布式ID生成器
和SnowFlake类似方法
利用redis的lua脚本执行功能,在每个节点上通过lua脚本生成唯一ID。
生成的ID是64位的:
- 使用41 bit来存放时间,精确到毫秒,可以使用41年。
- 使用12 bit来存放逻辑分片ID,最大分片ID是4095
- 使用10 bit来存放自增长ID,意味着每个节点,每毫秒最多可以生成1024个ID
比如GTM时间 Fri Mar 13 10:00:00 CST 2015 ,它的距1970年的毫秒数是 1426212000000,假定分片ID是53,自增长序列是4,则生成的ID是:
|
|
redis提供了TIME命令,可以取得redis服务器上的秒数和微秒数。因些lua脚本返回的是一个四元组。
|
|
客户端要自己处理,生成最终ID。
|
|
这种方案优缺点和Mongdb ObjectId大同小异
4.参考
[1] 浅谈数据库主键策略
[5] Twitter的分布式自增ID算法snowflake (Java版)
[6] 基于redis的分布式ID生成器
[7] 细聊分布式ID生成方法
[9] 百度唯一id